


 de
de 





















Compliance-Datenlösungen für multimodales KI-Training
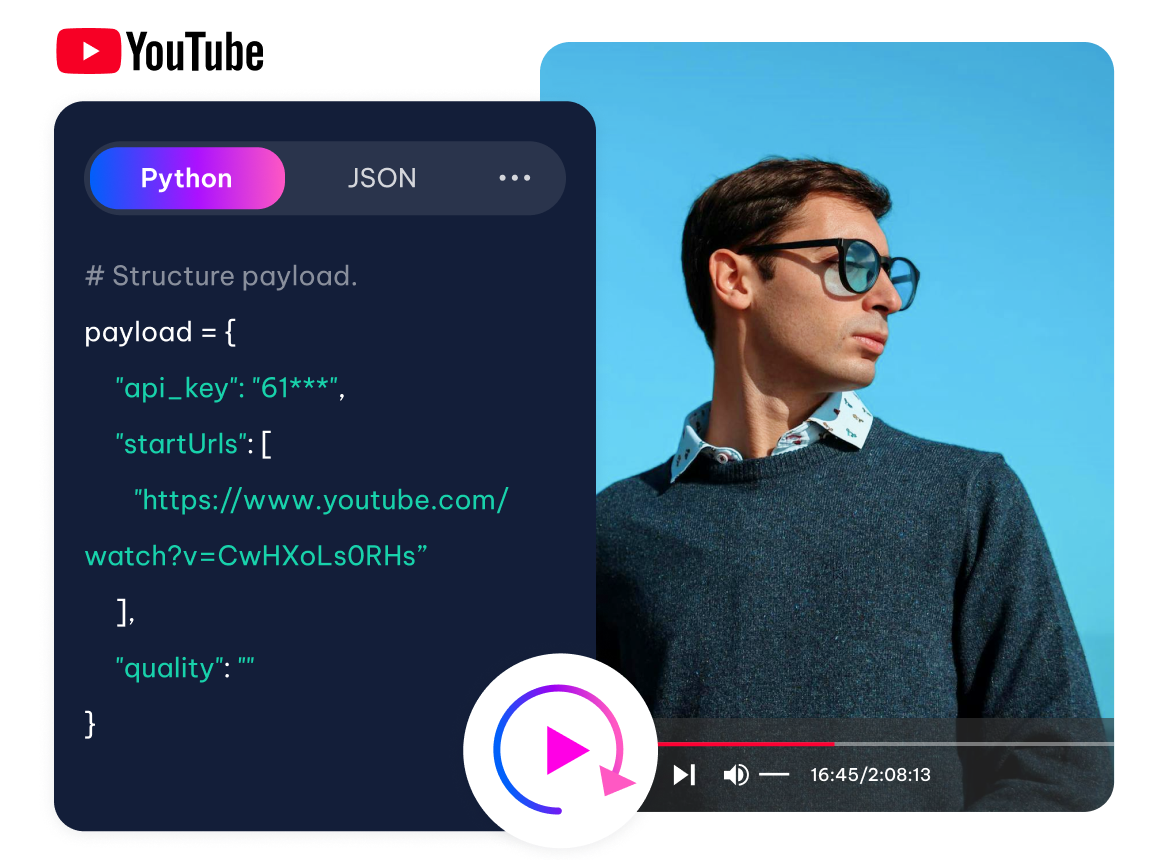
Strukturierte Datenerfassung
Separate Metadatenextraktion: Videoattribute + unabhängiger Audiostream (YouTube-kompatible Audio- und Videoquelle).
Datenabdeckung gemäß Originalspezifikation: Unterstützung von Full HD bis 8K-Datenquellen
Intelligente Parallelitätskontrolle: Automatische Planung von Millionen von Anfragen, Laden Balancing.
Automatisierter Trainingsdatenfluss
Cloud-Direktverbindungsarchitektur: URL eingeben und automatisch in den Trainingsspeicher übertragen.
Zero-Deployment-SaaS-Modell: Vollständige Online-Ausführung des Prozesses, keine lokale Umgebung erforderlich.
Tiefe Integration: Voreingestellte LLM-Datenvorverarbeitungsschnittstelle.
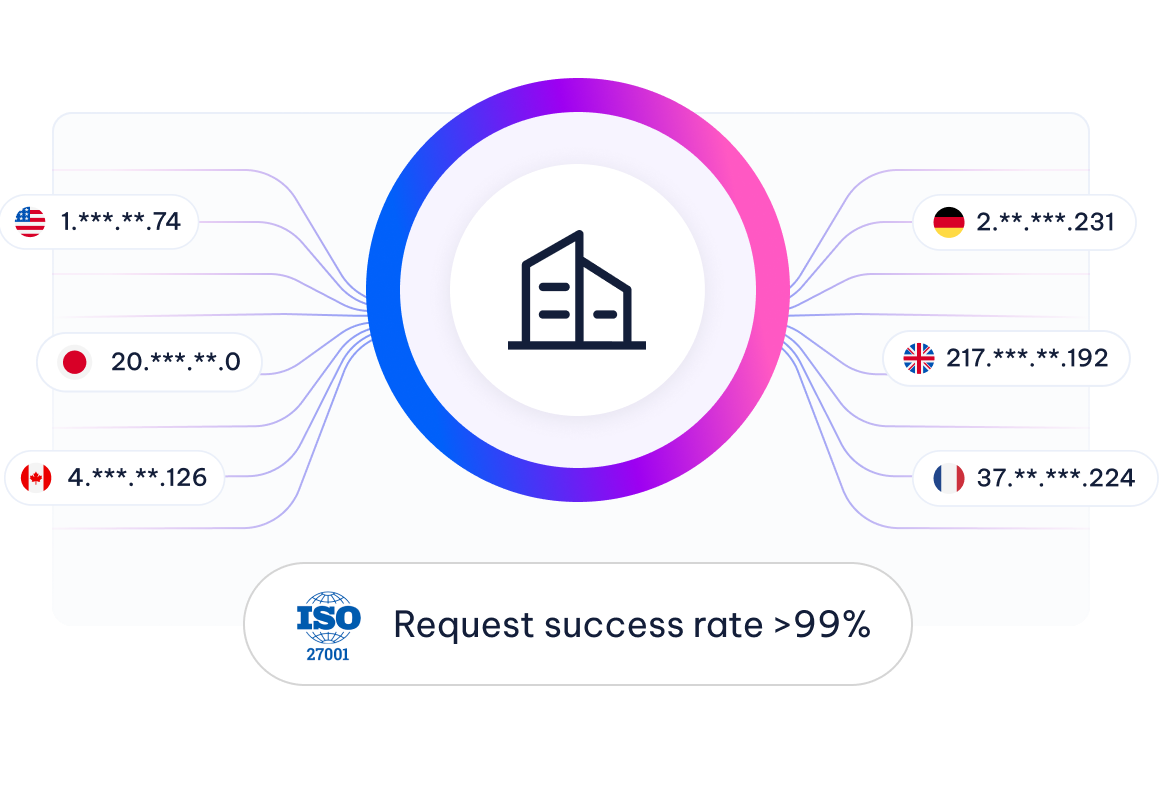
Zuverlässige Datenerfassung auf Unternehmensebene
Globale Compliance-Knoten: 195 Länder/Regionen, konforme private IP-Adressen.
KI-gesteuerter Abhörschutz: dynamische Fingerabdruck-Rotationstechnologie.
Intelligentes fehlertolerantes System: Anfrage-Erfolgsrate >99 % (ISO 27001) zertifiziert).
Out-of-the-box KI-Trainingsdaten-API
Einsatzbereite Datenquellen basierend auf konformen APIs, wodurch 90 % der Wartungskosten selbst erstellter Systeme entfallen
Architektur ohne Betriebs- und Wartungsaufwand
Keine Entwicklung und Bereitstellung erforderlich, wodurch die Datenentwicklungskosten um 80 % reduziert werden
10 Millionen Verarbeitungen täglich
Unterstützung für kontinuierliches Datenstreaming auf der YouTube-Plattform

Urheberrechtssicheres Framework
Automatisch eingeschränkte Filter Inhalte.

Cloud-native Bereitstellung
Direkte Verbindung zu AWS S3 und anderen Trainingsspeichern.
Kostenlose Erstellung konformer Daten-APIs
 "470.000 Trainingsdaten wurden am Tag der Bereitstellung verarbeitet, und die Compliance hat das interne Audit bestanden."
"470.000 Trainingsdaten wurden am Tag der Bereitstellung verarbeitet, und die Compliance hat das interne Audit bestanden." Leiter eines Medien-KI-Labors
Leiter eines Medien-KI-LaborsTechnischer Workflow zum Erstellen eines multimodalen Trainingssets
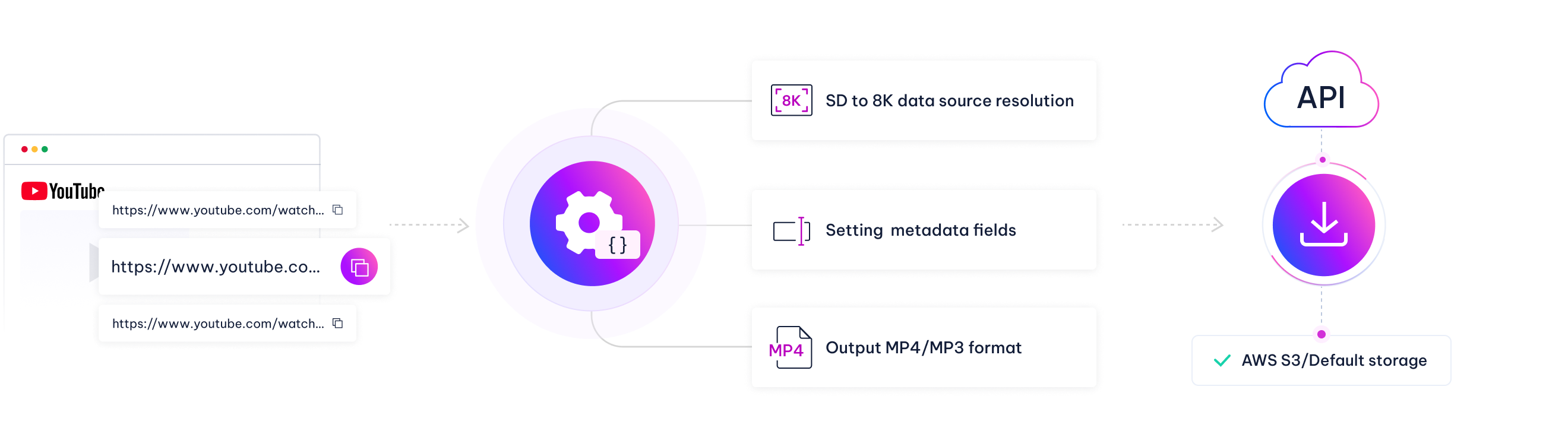

1. Datenquellenzugriff
Einzel-/Batch-Einfügung von YouTube-Video-URLs
2. Strukturierte Parameterkonfiguration
Auflösungsanforderungen: SD- bis 8K-Datenquelle
Metadatenfelder: Titel/Beschreibung/Untertitel/Audiostream usw.
Ausgabeformat: MP4/MP3
3. Automatisierte Ausführung und Bereitstellung
Trigger-API → Cloud-Verarbeitungs-Engine → Verschlüsselte Übertragung
Echtzeit-Statusverfolgung: Ausführungsliste
Direkter Cloud-Speicher: AWS S3/Standardspeicher
Sichere und konforme YouTube-Datenquelle
LunaProxy hält sich strikt an die folgenden Grundsätze:
Verarbeitet nur öffentlich verfügbare Daten
Filtert automatisch eingeschränkte Inhalte
Echtzeit-Verifizierung über die Content-ID-Fingerabdruckdatenbank
Vollständige Einhaltung von:
Nutzungsbedingungen der YouTube-API
DSGVO/CCPA-Datenschutzbestimmungen
Safe-Harbor-Grundsätze des Digital Millennium Copyright Act (DMCA)
Preise für die YouTube-Daten-API speziell für KI-Training
Transparente, gestaffelte Preise · Unterstützt die Erfassung von Millionen von Trainingsdaten
Benutzerdefiniert
Get a quote
Unlimited scalabilitys
Customized pricing
Additional feature
Contact Us
'%3e%3cpath%20d='M7%2013C8.65684%2013%2010.1568%2012.3284%2011.2426%2011.2426C12.3284%2010.1568%2013%208.65684%2013%207C13%205.34316%2012.3284%203.84316%2011.2426%202.75736C10.1568%201.67157%208.65684%201%207%201C5.34316%201%203.84316%201.67157%202.75736%202.75736C1.67157%203.84316%201%205.34316%201%207C1%208.65684%201.67157%2010.1568%202.75736%2011.2426C3.84316%2012.3284%205.34316%2013%207%2013Z'%20stroke='%23374459'%20stroke-linejoin='round'/%3e%3cpath%20d='M7%208V7C7.82842%207%208.5%206.32842%208.5%205.5C8.5%204.67158%207.82842%204%207%204C6.17158%204%205.5%204.67158%205.5%205.5'%20stroke='%23374459'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M7%2010C7.27614%2010%207.5%209.77614%207.5%209.5C7.5%209.22386%207.27614%209%207%209C6.72386%209%206.5%209.22386%206.5%209.5C6.5%209.77614%206.72386%2010%207%2010Z'%20fill='%23374459'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_8986_64148'%3e%3crect%20width='14'%20height='14'%20fill='white'%20transform='translate(14)%20rotate(90)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Erstellung konformer Trainingsdatensätze für multimodale KI-Modelle
Eine zuverlässige Pipeline, die täglich Millionen von Videometadaten verarbeitet
Maßgeschneiderte Unternehmenslösungen
Transparente Preise anzeigenLösung für Nutzerszenarien

KI-Unternehmen
Maßgeschneiderter, konformer Datenfluss auf Zehn-Millionen-Ebene.
Doppelzertifizierung nach DSGVO und ISO.
Spezielle Prüfung der Rechtskonformität.
Datenarchitektur beantragen

Entwickler
Vordefinierte multimodale Verarbeitungsvorlagen
Schneller Zugriff auf innerhalb von 15 Minuten
Kostenloses Testkontingent von 50 GB
API-Schlüssel erhalten

Forschungseinrichtungen
Nutzertypen für urheberrechtlich geschützte Ressourcen
Akademiespezifische Datenpakete
Open-Source-Datensätze auf Millionenebene
Akademische Ressourcen beanspruchen
